The primary goal for this challenge is to build a personal resume website that incorporates an API for site visit count tracking deployed using a fully functional CI/CD pipeline. The API itself is built upon a number of Google Cloud technologies via a Gitops-style approach. Ideally, the deployment of our API should be fully automated and include basic unit tests to verify integrity.
In this summary, I'll be going over how I built this site (pgbcloud.com) and deployed it to Google Cloud using Gitops methodology along with container and serverless technology. The specific Google Cloud services utilized in this challenge include:
- Storage
- Google Cloud Storage (GCS) (object storage)
- Firestore (NoSQL database)
- Compute
- Cloud Run (Serverless container-based compute)
- Networking
- Google Domains
- Cloud DNS
- Global HTTPS Cloud Load Balancer
- Cloud CDN (edge caching)
- Source Control
- Cloud Source Repositories (CSR)
- CI/CD
- Cloud Build
- Container Registry
As you might expect, trying to tie together all of these tools into a cohesive unit is quite a task your first time, so this was a good learning opportunity for me.
Before we dive into the specifics, let's take a look at the infrastructure diagram. Code for the front-end can be found here, and code for the back-end can be found here.
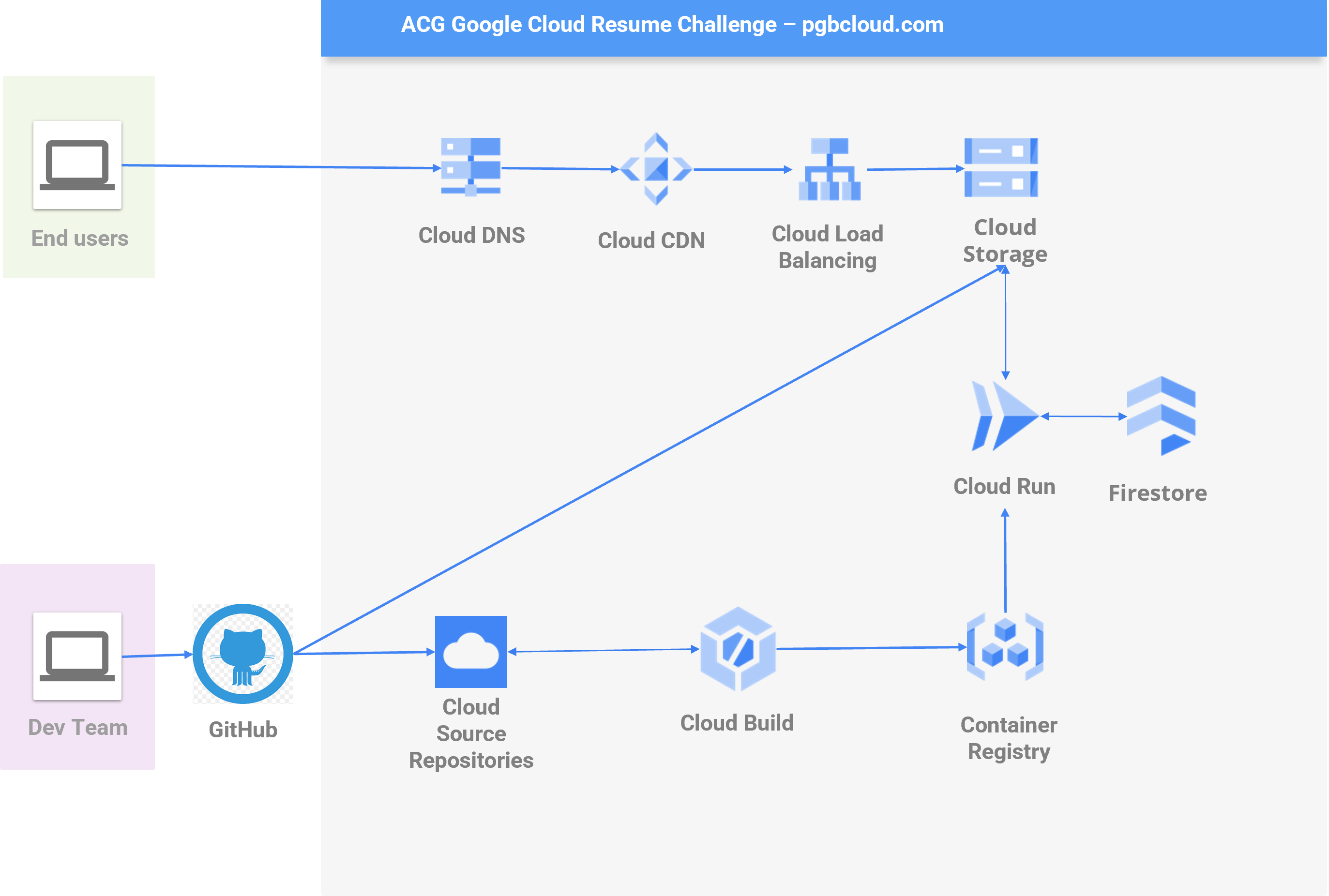
Run-Time Architecture Overview
The front-end of the site is built using HTML, CSS, and Javascript. Grid layout and basic styling is provided via the Bootstrap 5 web framework.
The site is designed to be a basic online resume and is served as a static asset via Google's Cloud Storage service. To help improve speed of delivery to end users, the site is cached via Google's global Content Delivery Network (CDN). With CDN, website content is cached and served close to users to greatly enhance site load speed.
On each load of the home page, a jQuery script is triggered to call our API located at api.pgbcloud.com to both log and retrieve an updating site visitor count. The count is then displayed in the right sidebar of the home page.
The domain is registered via Google Domains with nameservers pointed to Google Cloud DNS. Google offers a handy feature that manages your SSL certificates for you to allow HTTPS for your site. This is set up when creating an HTTPS load balancer, a tool this site uses to help manage incoming traffic in conjunction with Cloud CDN.
In terms of deployment, the website is deployed automatically to Google Cloud Storage using Github Actions which allows us to automate the process of pushing updated web files directly to GCS.
Dev-Time Architecture Overview
The primary role of our backend API is to allow our website to record page load counts. Each load of the home page triggers a jQuery AJAX call to our API which then records a new visit in a Firestore database and retrieves the current count.
As noted in the introduction, I used a Gitops approach to deployment that consists of the following flow of code from local development to production:
- API code is pushed from local env to Github repo
- Github repo is mirrored to Google Cloud Source Repository (CSR)
- CSR triggers a Cloud Build pipeline that:
- Runs unit tests on our app
- Clones our CSR repo to a different production repo on the candidate branch - This repo is not modified by humans
Once our application code has been pushed to the candidate branch of the env CSR repo, we are now ready to re-deploy our API via Cloud Run. A Cloud Build trigger is activated via push to the candidate branch and executes the following steps:
- Builds our app into a container
- Pushes the container to our Google Container Registry
- Deploys the new app to our Cloud Run service
- If successful, the finalized set of application deployment files are pushed to the production branch of our production repo
The reason we use two branches is so we can maintain a record of both successful and failed deployments. The candidate branch will store versions of code from all attempts to deploy our updated API, while the production branch stores only those versions of API code that resulted in successful deployment to Cloud Run.
Key Tradeoffs
I felt that the architecture was well designed for this challenge. There were several parts of the project that allowed some leeway in terms of implementation choice. For example, I decided to use GitHub Actions to implement the CI/CD pipeline for my front-end simply as a learning exercise. I may go back and re-write that piece to use Cloud Build instead just to keep everything in the Google Cloud ecosystem.
I also opted to use Container Registry instead or Artifact Registry due to the simple integration with Cloud Run. I believe Artifact Registry is in beta at the time of this challenge, but I'll be rearchitecting this project to use AR in the near future. The reason for this is that AR will eventually supersede CR.
Also of note, this project did not implement distributed counters due to the relatively low traffic I expect to receive...though I'm happy to implement this if my resume does receive lots of traffic. :)
Next Steps
There are a few things I would like to spend more time on in the coming weeks/months:
- Utilize Terraform to set up the project infrastructure as code
- Revisit API to determine if the current Flask implementation is the lowest latency option. Perhaps something on NodeJS would be faster?
- Continue building out the resume site to better handle mobile devices
- Work on local dev environment to ensure best practices are being implemented for service account authentication
- Architecture diagrams - As I was building my architecture diagram I realized I wasn't sure how detailed I should be. I need to investigate best practices for diagramming.
Lessons Learned
Wrapping my head around the Gitops process was probably the trickiest part of this challenge for me. Everything else seemed fairly straightforward, but I also need to go back and review each step to ensure I'm using best practices.
I learned a lot about Gitops via the various tutorial articles and other documents I found online, and it's something I plan to implement into my other projects. I really like being able to keep an accurate record of attempted deployments vs successful deployments.
That simple, distinguishing split between branches is going to be extremely useful.
I believe I have some redundant build steps in my deployment that need to get cleaned up, so I'll be taking care of that soon to make my Gitops CI/CD pipeline more efficient.
I really wish I had more time to implement the Terraform code necessary to build this infrastructure. After the challenge ends, my first goal is going to involve focusing on infrastructure as code and taking a few courses on proper implementation.
I'm excited to keep applying these new skills I've learned. I had never used tools such as Cloud Build or Cloud Run before this challenge, but knowing that I could get them up and running in a day or two just by reading the docs has given me a nice confidence boost.
Looking forward to learning more!